

Jenkinsで定常作業を自動化し、開発に集中できる環境を整えた件

こんにちは。朝Alexa君よりちょっと早く起きれたらちょっと嬉しい、
エンジニアのふるやです🙃
今回は『Jenkinsで定常作業を自動化し、開発に集中できる環境を整えた件』について、ご紹介します。
◆経緯
エンジニアを「ステージング環境へのデプロイやデータ反映、QA時のバッチ実行から解放したい!」
エンジニアが「開発に集中するための環境を作りたい!」
想いがありました。
こちらの対応手段として、管理画面を改修する手もありますが、
物によってはイベントごとに細かい処理を追加する必要がある構造のため、コストが大きく感じていました。
そこで、ある程度汎用的に使えるものは「Jenkinsで自動化させよう!」
と思い立ちました。
◆Jenkinsとは?
Build great things at any scale
The leading open source automation server, Jenkins provides hundreds of plugins to support building, deploying and automating any project.
一言で言うと「自動化ツール」です😁
様々なプラグインがあり、外部サービスとの連携が容易なのも魅力です。
◆Jenkinsの運用について
◇ステージング環境でのみ使用する
※誤操作による本番に影響を回避する為、本番では使用していません。
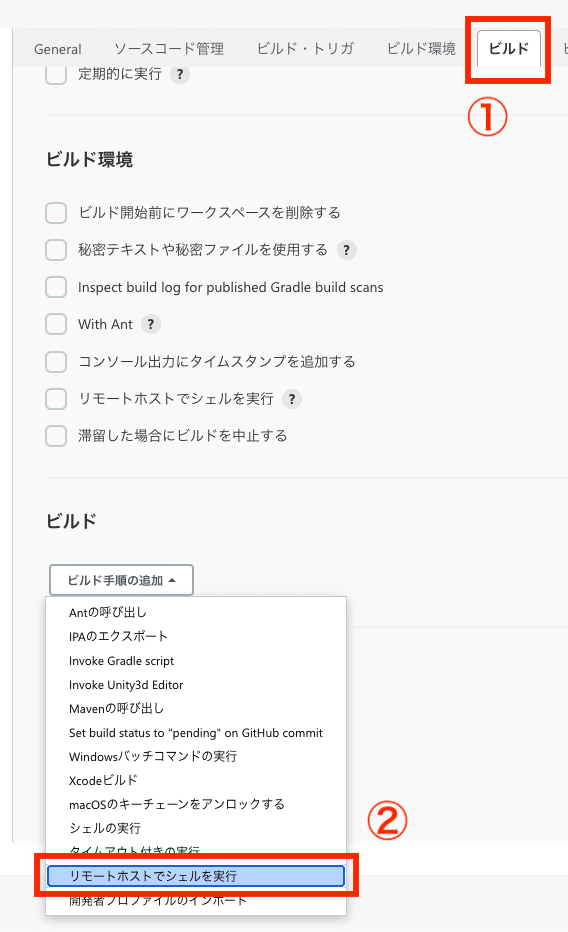
◆自動化した内容の一部
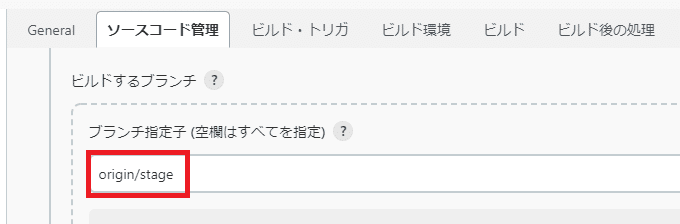
◇ソースコードをデプロイする
既にジョブを手動で実行しデプロイできるようにしていました。
今回はその手動の煩わしさを解消するために「SCMポーリング」を使用し、
指定ブランチへのプッシュを検知 → デプロイが自動実行
されるようにしました。
SCMポーリング設定
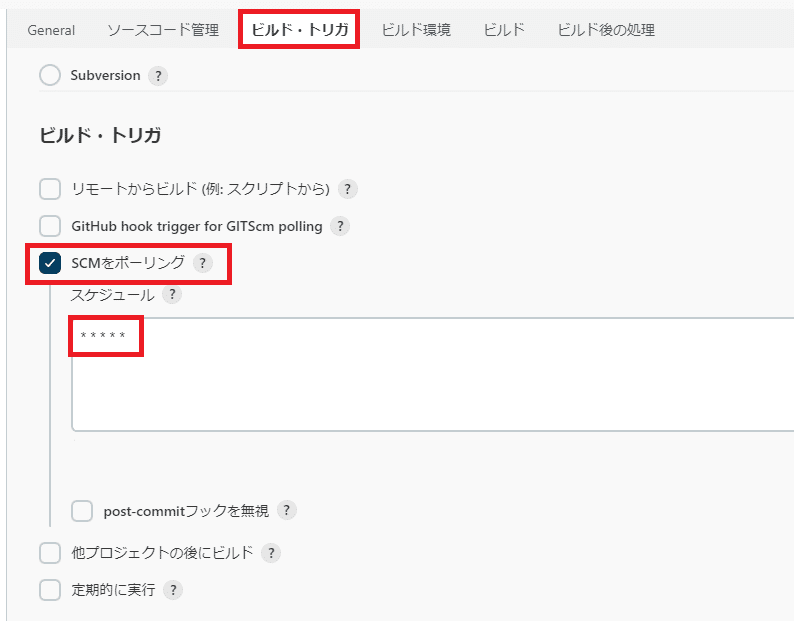
スケジュール
以下の通り、cronの記法で毎分チェックしています(必要に応じて変更してください)
* * * * *◇SQLを反映する
パラメータ
SQLPATH : 反映するSQLファイルのパスを指定します
Shell
echo $SQLPATH
cd /data/git/doc/${SQLPATH%/*}
sudo /bin/mysql -uhoge -pfuga < /data/git/sql/$SQLPATH◇httpdを再読み込みする
データベースの負荷軽減の為、マスタデータはAPCキャッシュを使用しています。
既に反映されていたデータがあり、ユーザーが該当データを参照している場合、修正してデータを反映しても反映内容を確認できません。
反映した内容を確認するためには httpd を reload あるいは restart し、
APCキャッシュを削除する必要があります。
こちらは上記「SQLを反映する」ジョブの下流プロジェクトとして設定し、
「SQLを反映する」ジョブが正常に完了した場合のみ、自動で実行されるようにしました。
今回はステージング環境を確認されている方を考慮し、
httpd reload を使用します。
事前に httpd reload の実行内容を httpd.service にてご確認ください。
graceful が指定されている場合は実行中のプロセスを Kill しないので、
運営中のサービスに影響はありません。
$ cat /usr/lib/systemd/system/httpd.service
---
[Unit]
Description=The Apache HTTP Server
After=network.target remote-fs.target nss-lookup.target
Documentation=man:httpd(8)
Documentation=man:apachectl(8)
[Service]
Type=notify
EnvironmentFile=/etc/sysconfig/httpd
ExecStart=/usr/sbin/httpd $OPTIONS -DFOREGROUND
ExecReload=/usr/sbin/httpd $OPTIONS -k graceful
ExecStop=/bin/kill -WINCH ${MAINPID}Shell
sudo systemctl reload httpd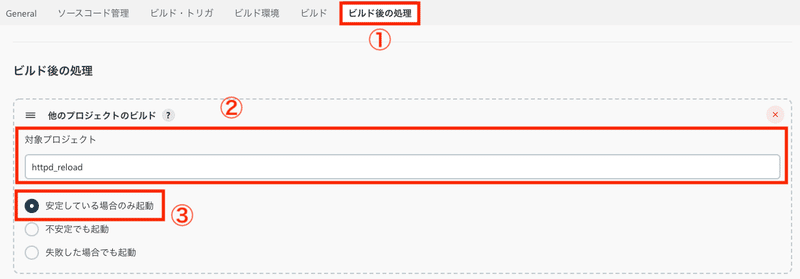
◇該当データを削除する
パラメータ
EV_ID : イベントIDを指定します
PLAYER_ID : プレイヤーIDを指定します
※プレイヤーIDの指定がない場合は全プレイヤーを対象にしています
Shell
echo $EV_ID
echo $PLAYER_ID
if [ $PLAYER_ID -eq "0" ] ; then
/usr/bin/mysql -uhoge -pfuga -e 'use event; DELETE FROM `event_player_data` WHERE ev_id = '$EV_ID';'
else
/usr/bin/mysql -uhoge -pfuga -e 'use event; DELETE FROM `event_player_data` WHERE ev_id = '$EV_ID' AND player_id = '$PLAYER_ID';'
fi◆ビルド後
今回はChatworkへの通知例です。
通知内容にはコンソールテキストへのリンク、
「SQLを反映する」ジョブは反映したSQLファイルのパスを含めています。
成功
[info][title]【プロジェクト名:STG】SQL反映[/title](clap)SUCCESS[/info]
http://jenkins.hoge.net/view/project/job/deploy_to_stg/$BUILD_NUMBER/consoleText
* SQLPATH : $SQLPATH失敗
[info][title]【プロジェクト名:STG】SQL反映[/title](devil)FAILURE[/info]
http://jenkins.hoge.net/view/project/job/deploy_to_stg/$BUILD_NUMBER/consoleText
* SQLPATH : $SQLPATH今回は以上ですが、これら以外にも様々なことを自動化しています。
プランナーさんやQAさんが自ら調整したいことをできるようになりました(エンジニアのコストも低減しました😄)
効率化を考えて自動化していくのは楽しくもあるのでオススメです!
◆過去に投稿した自動化関連の記事
今後も自動化できる箇所は対応し、作業者が開発に集中できるように
効率化を図っていこうと思います😎
以上、エンジニアのふるや(@h_furuya_)が綴らせていただきました。